Migrating from MongoDB to Postgres: Part 1

This is the first part of an upcoming series documenting our work in migrating databases from MongoDB to Postgres. We did this with zero incidents, having planned the changes over 6 weeks, and executed them in under an hour. We’d love to share our thoughts on how we approached it and what things worked for us.
Why change?
In the beginning, we used MongoDB. This was useful in the early stages of prototyping and getting Jam in the hands of users as quickly as possible but we realized that we would need a better way to model and constrain our data. Over time, we added new products and features like teams, integrations, and instant replays which were very much related to other data collections. Using a document store didn’t make sense.
We chose Postgres because it is stable, mature, and fast. We wanted better data integrity and control over the schema. SQL lends better to complex querying over multiple tables than MongoDB’s aggregate pipelines.
Changing the data layer was not an easy feat but we managed to do it without incidents. They say “a journey of a thousand miles begins with a single step” and for us, that first step was getting Postgres integrated into our local environment. So let’s take a look into how we set that up with.
Developer tooling!
It is paramount that our local development environment is pleasant to work with — especially as we scale our team up. Our goal was to avoid arcane workflows and having to share complex configurations and code snippets. Setting up a local database and making changes should be easy!
From past experience, onboarding engineers sometimes run into weird hurdles with infrequently configured systems like databases. To mitigate this pain, we codified and automated most of the basic operations so that other engineers on the team could get started as quickly as possible.
Scripting
Our application tier consists of Node.js-based services written in Typescript. There are several internal packages that we maintain.
In our database package, we created a few npm scripts for commonly used operations. We asked ourselves “What are the most common interactions we have with the database?” and automated them.
A typical command would be used like this:
$ yarn workspace @jam/database postgres:provisionThe most useful commands we created were:
provision - sets up a blank Postgres Docker container. We decided on using Docker for portability although we could have automated some kind of system install of Postgres.
We also mount a volume to /docker-entrypoint-initdb.d containing some bootstrapping shell scripts. When the container is first created, it will scan this well-known directory for executable .psql or .sh files and runs them. Here’s an example script that sets up some basic entities like a database and a superuser.
#!/bin/bash
set -e
psql -v ON_ERROR_STOP=1 -U postgres <<-EOSQL
CREATE DATABASE jamtest;
CREATE USER dev WITH PASSWORD 'dev';
ALTER USER dev WITH SUPERUSER;
EOSQLmigrate <up|down|create> - Database migrations. We use sequelize to modify our schema or run ETL changes in the database. We try to commit all major database changes to the repo. Having all migrations checked in means we can reproduce conditions that our applications were experiencing. In cases where we need to fix a column of table, it’s better for us to run migrations rather than an engineer logging into a psql session and ad-hoc changing things.
Migrations are run automatically as part of our CI deployment so that a container runs migrate up before the applications are rolled out. If we have a breaking change, we must break out into multiple staged releases to handle backwards compatibility.
import - This script is vital to our new database setup. This runs pg_dump on a remote Postgres instance (we only target staging so we aren’t having to scrub PII) and subsequently pg_restore into our local databases. This was also containerized so we don’t have to install postgres directly onto our hosts.
An alternative approach to populating a database is scaffolding data. We toyed with the idea of setting up scaffolding scripts to insert dummy data but figured importing live staging data would suffice. Both approaches are totally valid. Scaffolding would offer more control over what the data looks like.
psql:[dev|staging|production] - quick access to psql shell connecting to various environments.
help - this is the bare minimum help prompt we could implement. We wanted to ensure the tooling is easy to navigate but didn’t need to invest time into a full-blown CLI so we wrote a simple shell script to echo a static help description. We use npm scripts with a simple namespace scheme and point to other shell scripts:
$ yarn run postgres
Usage:
postgres:<command>
Supported environment variables are:
POSTGRES_DATABASE (default: jamdev)
POSTGRES_USER (default: postgres)
POSTGRES_PASSWORD (default: postgres)
POSTGRES_PORT (default: 5432)
POSTGRES_HOST (default: undefined)
POSTGRES_CONNECTION_URL (optional: supercedes above vars)
Commands:
provision set up postgres docker container
psql:{dev|staging|prod} launch interactive psql shell
proxy:{dev|staging|prod} create a proxy tunnel (foreground)
import:{staging|prod} import a snapshot of staging or prod into dev postgres
remove remove container
start start container
stop stop container (send SIGTERM)
migrate migration (umzug CLI)
migrate:create create new migrationThe package.json scripts looked something like this:
Deferred configuration
To reinforce our guiding principle of “easy-to-use”, we rallied behind the idea of minimal context required. Our thinking is that a new engineer does not need to know exactly what env variables, flags, or files are needed right away. Reading a README.md file or a wiki page is sufficient but kind of cumbersome.
Instead of bridging gaps with additional documentation, we decided to make the scripts fail quickly and loudly when applicable. We let the user know when something is missing or misconfigured in the CLI.
When someone needs to connect to a psql shell, they run:
$ yarn run postgres:psql:stagingBut if they haven’t configured a certificate and user credentials we print out helpful warnings that explain what variables are required, and where exactly to get them. This kind of in-the-flow guidance is incredibly simple and but it is quite effective:
$ yarn run postgres:psql:staging
Missing $POSTGRES_SERVICE_ACCOUNT_CERT_PATH. This is required to authenticate with the remote postgres instance.
1. Create a key for the developer db sevice account at https://console.cloud.google.com/iam-admin/serviceaccounts/details/<REDACTED>/keys?project=<REDACTED>, download it, and add its path to your `.env` as `POSTGRES_SERVICE_ACCOUNT_CERT_PATH`
2. Get the `POSTGRES_PASSWORD` env var from 1Password and put it in your `.env`Automate the boring bits
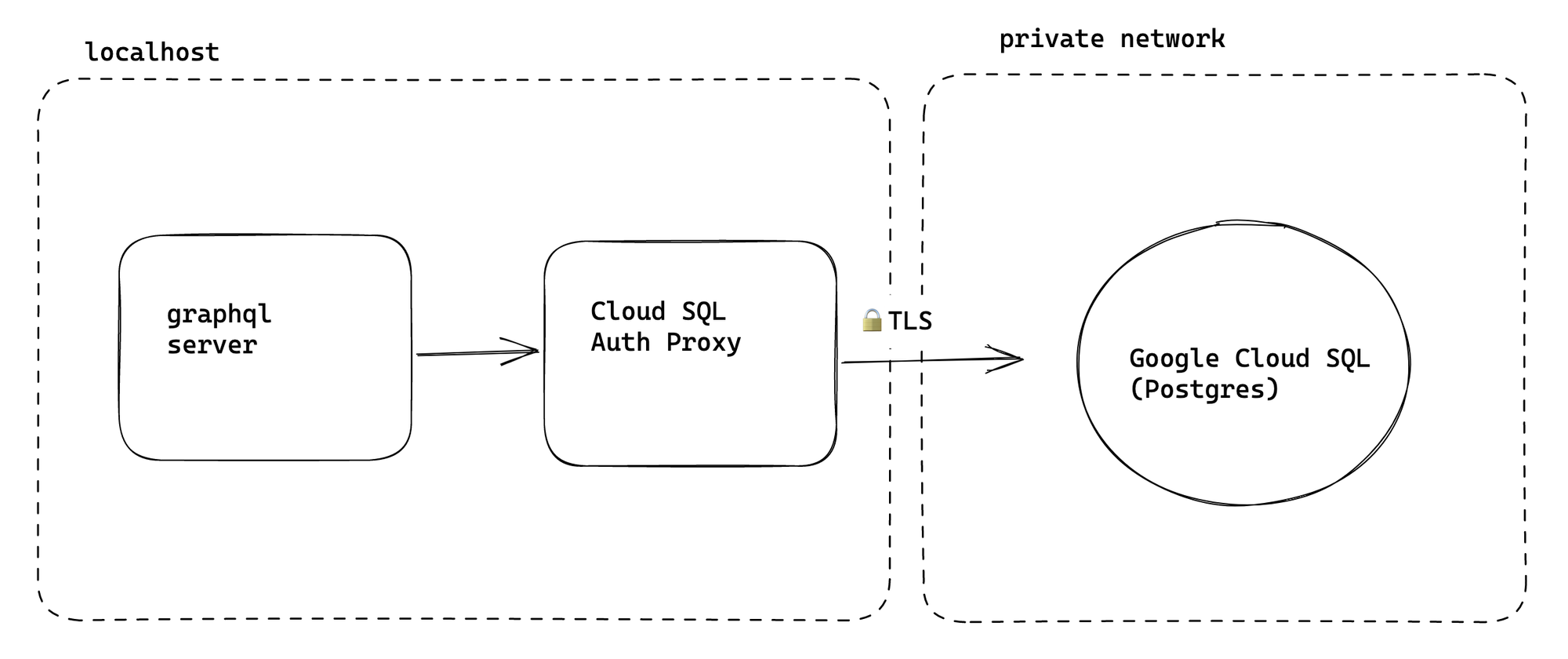
Some of the infrastructure knowledge is required but not really important for day-to-day flow so we try to abstract and automate as much of it as possible. One example of this is how we connect to remote instances of Postgres. Underneath the covers, we run a proxy, but it is opaque and just looks like you immediately connect to a psql shell.
We use Google Cloud SQL for our managed Postgres. We don’t connect directly to the Postgres instances which are only accessible to authorized networks (controlled by CIDR ranges).
So to access our managed instances we use https://cloud.google.com/sql/docs/sqlserver/connect-docker to connect. This tool essentially provides a secured TCP tunnel to a bastion host within the Google Cloud private network. Our scripts will automatically run a transient proxy container in the background while our local services and tooling point at the proxy:
$ yarn run postgres:psql:staging
psql (15.2 (Debian 15.2-1.pgdg110+1), server 14.4)
Type "help" for help.
staging=>Was it worth it?
Yes! Regardless of what database system we ended up migrating to, we think these common workflows will be useful to nail down. As we will mention in a later post, we needed to perform ETL from MongoDB. The ETL was performed as a series of SQL migrations instead of ad-hoc scripts.
The upfront tooling investment was well worth it because we could migrate up, debug, rollback, or even start from scratch with just a few commands.